






はい、相変わらずに続きで〜す

データライフサイクルを追う
データにも生命と同じようにライフサイクルがある
計画、取得、管理、分析、保管、破棄、のフェーズがある。データそのもののライフサイクルとデータ分析ライフサイクル(問いかけ、準備、処理、分析、共有、行動)とを混同しないように注意。
データ分析プロセス
問いかけ、準備、処理、分析、共有、行動のそれぞれのフェーズでどのような振る舞いをするかの詳細を学んでいく。
一つの前段階として、学習ログで使ったデータを表で整理する振り返りを行う、
振り返り
「雀魂における直近5局の順位、得点」を取得するデータにしたので表にまとめる。うん、まとめた。
| 局目 | 順位 | 点数 |
| 1局目 | 4位 | 17300点 |
| 2局目 | 1位 | 40800点 |
| 3局目 | 1位 | 75300点 |
| 4局目 | 3位 | 17900点 |
| 5局目 | 4位 | 19700点 |
スプレッドシートの基本の取得
スプシはさんざん使ってるから基本は大丈夫かな〜。
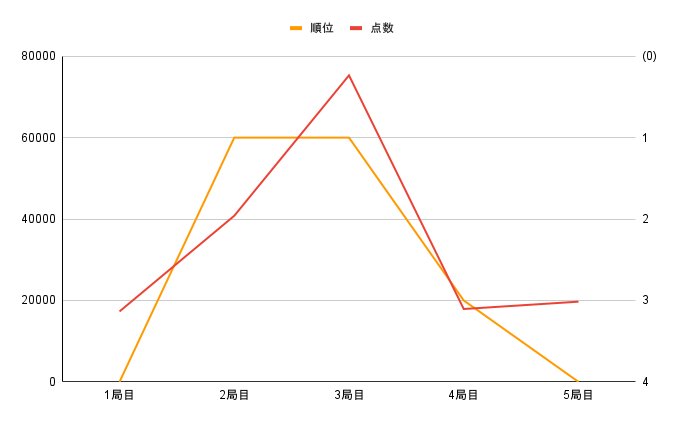
直近の麻雀の順位と点数を可視化した。順位の場合一位が上にきてないと変なので、そこの部分を表現するのに少し手間取った。https://auto-worker.com/blog/?p=2039のサイトを参照にしました。ありがとう。
構造化クエリ言語(SQL)
これが一番やりたかった〜、ようやくたどり着いたぜ。
SELECT、FROM、WHEREが基本の構文で、それぞれ 以下を選択するものだと。うんうん、なるほど。
SELECT を使用して、返す列を選択します。
FROM を使用して、必要な列が存在するテーブルを選択します。
WHERE を使用して、特定の情報をフィルタします。
SELECT
求める列
FROM
データを含むテーブル
WHERE
特定条件
という形が基本の形で、構文エラーを減らすらしい。直感的には、テーブルを指定して、求める列を指定して、条件を指定するという流れが自然な用に感じるが、列→テーブル→特定条件、という条件らしい。間違えそ〜。
複数条件の場合、SELECTコマンドではカンマ区切り、WHEREコマンドはAND(やOR,NOTなどのコネクタ/演算子)を使用する。なるほど、場所ではなくて条件指定であるWHEREコマンドは自由度が高い表現ができるようになっているのね、理解。
SQLの無限の可能性
大文字、インデントを使用すると情報が読みやすくなる。インデントというのは、字下げをして空白を入れることね。
SQLステートメントの最後にはセミコロン(;)をつけること、これが終了の合図。なくてもいける場合があるらしい。
WHERE条件
完全一致ではない、文言も引き出すことができる。
完全一致の場合(field1の列の条件を指定したい場合)は、
WHERE
field1=’〇〇’
部分一致でデータ抽出したい場合は
WHERE
field1 LIKE’〇〇%’
で、それぞれデータが抽出される。ワイルドカード(任意の文字の部分↑だと%の部分)がアスタリスク(*)で表現される場合もあるらしい。
すべての列をSELECTする
SELECT*ですべての列を選択することができる。ただしデータ量が膨大になる場合は実行に時間がかかるため注意が必要
コメント
カラム名やテーブルの名前から、意味を把握しにくいような場合はコメントを適宜いれることで、何を実行したいのかが一目でわかるようになる。
コメントは「/*コメントコメント*/」「–コメントコメント」のような形で表記することでコメントとして認識される。クエリのステートメント内部以外でも、クエリ自体の説明などに使うことも可能。
エイリアス
AS句を使うことで、クエリ実行中に割り当てをすることができる。
クエリ内での呼称を統一したい場合に便利。データベースのテーブルには影響を与えない。
field1 AS last-name — 作業用のエイリアス
みたいな感じで、使う。(上記は、field1ってカラムがラストネームを指しているけど、field1って名称のままだと分かりづらいから、このクエリ内ではラストネームって呼ぶことにするよって宣言をしたということ)
振り返り
基礎的な概念としてはだいぶ理解した気がする。実際自分が書いたSQLが動いてくれると嬉しい。
今後は以下のサイトでも練習をしながらやってみよ〜

コメント
[…] 【ログ】日本リスキリングコンソーシアム経由でGoogleデータアナリティクス講座受けてみた④はい、相変わらずに続きで〜すデータライフサイクルを追うデータにも生命と同じようにラ […]